Основные принципы[]
Шина PCI является синхронной: состояние большинства её сигналов играет роль только в момент положительного перепада синхросигнала CLK, означающего начало очередного такта шины. Устройство, управляющее тем или иным сигналом, должно обеспечить его правильное состояние за определённое время до фронта CLK и удерживать его некоторое время после прохождения фронта (точные величины этих времён зависят от частоты шины), после этого состояние сигнала может быть произвольным до момента, предшествующего следующему положительному перепаду CLK, т.е. началу нового такта шины. Исключением являются асинхронные сигналы RST#, INTA#, INTB#, INTC#, INTD#, CLKRUN# и PME#: они являются действующими тогда, когда на них находятся активные (низкие) уровни независимо от состояния линии CLK.
Основные операции передачи данных (транзакции) выполняются в пакетном режиме (burst mode). Каждый состоит из фазы адреса и одной или нескольких фаз данных.
Шина PCI в общем случае имеет древовидную структуру и состоит из сегментов, обычно также именуемых шинами. Один из сегментов является корневым: он прямо (через мост Host–PCI) или косвенно (через другую шину и соответствующий мост, например, DMI–PCI) подключен к процессору. К корневому сегменту через мосты PCI–PCI присоединяются другие сегменты шины PCI, к ним, опять-таки через мосты, могут подключаться следующие сегменты и т.д. За исключением необходимости настройки, наличие мостов совершенно прозрачно для программного обеспечения: оно просто обращается к нужным устройствам по назначенным им адресам, «не задумываясь» о том, на каких именно сегментах PCI (и вообще, на шинах каких типов) эти устройства находятся.
Управление передачей[]
Управление передачей информации по шине PCI осуществляется главным образом тремя сигналами — FRAME#, IRDY# и TRDY#, остальные сигналы играют вспомогательную роль.
Пока оба сигнала FRAME# и IRDY# отсутствуют, шина находится в состоянии бездействия (idle state). Первый такт после появления сигнала FRAME# является фазой адреса, начинающей транзакцию шины. В этот момент все устройства на шине анализируют состояние линий AD и C/BE#, по которым одновременно с сигналом FRAME# выдаются адрес устройства и код операции, которая будет выполняться в данной транзакции. Фаза адреса длится один или два такта (последнее имеет место при выдаче 64-разрядного адреса на 32-разрядной шине или на 64-разрядной, работающей в 32-разрядном режиме; при этом используется операция «двойной цикл адреса»).
После окончания фазы адреса начинаются фазы данных. Каждая фаза занимает минимум один такт и заканчивается, когда в одном такте будут одновременно активны сигналы IRDY# и TRDY# либо сигналы IRDY# и STOP#. Источник данных (задатчик в операции записи, исполнитель в операции чтения) выставляет на линии AD необходимые данные, а на линии C/BE# — сигналы, показывающие, какие именно байты AD содержат реально передаваемую информацию. После этого он выдаёт свой сигнал готовности (IRDY# в операции записи, TRDY# в операции чтения). Приёмник данных активным сигналом готовности (TRDY# при записи, IRDY# при чтении) оповещает источник о том, что он способен осуществить приём. Выдача данных не привязана к приёму: источник выдаёт их так быстро, как только может, и выставляет соответствующий сигнал готовности, а потом ожидает появления сигнала готовности приёмника, после чего начинается новая фаза данных или транзакция завершается.
В последней фазе данных задатчик, выдавая сигнал IRDY#, одновременно снимает сигнал FRAME#. После того, как исполнитель примет или передаст последнюю порцию данных и выдаст сигнал TRDY#, транзакция завершается (concluse), и шина переходит в неактивное состояние. Если исполнитель желает прервать (terminate) транзакцию до её логического завершения, он выдаёт сигнал STOP#, после чего задатчик снимает FRAME#, и шина переходит в состояние бездействия.
Задатчик, выставив сигнал IRDY#, независимо от состояния линии TRDY# не может менять IRDY# или FRAME# до тех пор, пока текущая фаза данных не завершится. Исполнитель, выставивший сигнал TRDY# или STOP#, не должен менять их или сигнал DEVSEL# до завершения фазы данных.
Адресация[]
Устройства на шине PCI используют три физических адресных пространства: памяти, ввода-вывода и конфигурационное. Последнее используется для настройки устройств и назначения им диапазонов адресов в пространствах памяти и ввода-вывода.
В начале каждой транзакции все устройства сравнивают указанный в ней адрес с назначенными им диапазонами адресов. То устройство, в чей диапазон попадает заданный в транзакции адрес, и будет участвовать в ней в качестве исполнителя.
Декодирование адресов ввода-вывода[]
Шина PCI использует 32-разрядную адресацию портов ввода-вывода. В фазе адреса задатчик указывает точный адрес младшего из байтов, к которому осуществляется обращение. Для передачи значащих байтов будут использоваться те линии AD, которые соответствуют положению этих байтов в двойном слове. Например, если выполняется чтение байта из порта 00001012h, то в фазе адреса будет задан именно этот адрес, а сам байт будет находиться на линиях AD[23:16], чему соответствует комбинация 1011 на линиях C/BE[3:0]#.
Линии разрешения байтов C/BE# должны соответствовать двум младшим разрядам адреса порта. Допустимы следующие комбинации:
| AD[1:0] | Начальный байт | Допустимые значения C/BE[3:0]# |
| 00 | Байт 0 | xxx0 или 1111 |
| 01 | Байт 1 | xx01 или 1111 |
| 10 | Байт 2 | x011 или 1111 |
| 11 | Байт 3 | 0111 или 1111 |
Устройство может ограничивать допустимые типы запросов к адресному пространству ввода-вывода. Например, оно может требовать, чтобы некоторый порт читался и записывался только как полное двойное слово. В этом случае, обнаружив недопустимое обращение, устройство прерывает транзакцию (target-abort).
Устройства могут иметь порты, располагающиеся по фиксированным адресам. Такие устройства называются унаследованными (legacy); к ним относятся, например, все видеоадаптеры, поскольку они способны эмулировать функциональность устаревших плат VGA. Программное обеспечение, проводящее конфигурирование устройств, должно заранее «знать» о том, какие порты заняты унаследованными устройствами.
Декодирование адресов памяти[]
Обращения к памяти всегда выровнены по границе двойного слова, поэтому устройства, декодируя адрес, заданный в транзакции, анализируют лишь разряды AD[31:2].
Разряды AD[1:0] определяют порядок передачи данных, запрашиваемый задатчиком:
- 00 — последовательное увеличение адреса;
- 01 — зарезервировано, отсоединение после первой фазы данных;
- 10 — режим свёртывания строк кэша;
- 11 — зарезервировано, отсоединение после первой фазы данных.
Примечание. В более ранних версиях спецификации комбинация 01 имела особый смысл, поэтому некоторые старые задатчики могут генерировать, а исполнители — отвечать на такие запросы. Новые устройства не должны использовать эту комбинацию.
Все исполнители должны проверять разряды AD[1:0] и затем либо выполнять пакетную передачу в запрошенном режиме, либо прекратить транзакцию одним из двух способов: отсоединением с данными (disconnect with data) в течение первой фазы данных или отсоединением без данных (disconnect without data) во второй фазе. В любом случае производится одна передача данных, что позволяет полностью выполнить требуемую операцию, пускай и медленно (по одной фазе данных на транзакцию, а не в пакетном режиме).
Устройство может вообще не поддерживать пакетную передачу; в таком случае любой обмен данными выполняется, как описано выше — с прекращением каждой транзакции после выполнения одной фазы данных. Если пакетный режим поддерживается, обязательно должен поддерживаться режим передачи с последовательным увеличением адреса; возможность передачи со свёртыванием строк кэша может отсутствовать.
При передаче с последовательным увеличением адресов после каждой фазы данных адрес увеличивается на 4 или 8 для 32- и 64-разрядной операции обмена соответственно (особенности 64-разрядной адресации будут описаны отдельно). Таким образом, этот способ позволяет прочитать или записать большие непрерывные области памяти за одну транзакцию. С помощью линий C/BE# в каждой фазе данных осуществляется выбор отдельных байтов в пределах каждого двойного или учетверённого слова, которые реально участвуют в передаче; допускается наличие пустых фаз данных, в которых не читается и не записывается ни одного байта. Однако адрес после каждой фазы данных в любом случае увеличивается на 4 или 8 независимо от числа байтов, действительно участвующих в операции. Транзакции типа «запись в память и инвалидация» могут выполняться только в режиме последовательного увеличения адресов.
Передача со свёртыванием строк кэша позволяет в одной транзакции считать или записать одну строку кэша исполнителя целиком. Размер строки задаётся соответствующим конфигурационным регистром. Операция может начаться с произвольной позиции внутри строки, при этом адрес увеличивается на 4 или 8 после завершения каждой фазы данных. Когда будет достигнут конец строки, адрес будет модифицирован таким образом, чтобы указывать на её начало, после чего транзакция продолжается до тех пор, пока не будет считана или записана оставшаяся часть строки кэша. Например, если размер строки кэша составляет 16 байт, а чтение началось с адреса 8 и ведётся в 32-разрядном режиме, будут выполнены следующие фазы данных:
- считывание двойного слова по адресу 8;
- считывание двойного слова по адресу C;
- считывание двойного слова по адресу 0;
- считывание двойного слова по адресу 4.
Если после передачи строки кэша целиком транзакция не завершается, она будет продолжена для следующей строки кэша, причём начнётся с той позиции в следующей строке, с которой началась в предыдущей. Для приведённого примера после первых четырёх последуют следующие фазы данных:
- считывание двойного слова по адресу 18;
- считывание двойного слова по адресу 1C;
- считывание двойного слова по адресу 10;
- считывание двойного слова по адресу 14.
Если поддержка кэша в исполнителе не реализована и он не имеет регистра размера строки кэша, он прекращает транзакцию с отключением, выполняя лишь одну фазу данных; в этом случае вся порция данных будет передана с помощью нескольких транзакций — по одной фазе данных на транзакцию.
Устройство может требовать выполнения обмена с ним только определёнными порциями данных (байтами, словами или двойными словами). Если оно обнаружит нарушение этого требования, оно прерывает транзакцию (target-abort).
Декодирование адресов конфигурационного пространства[]
Все устройства на шине PCI, за исключением мостов Host–PCI, должны иметь собственное конфигурационное адресное пространство. Мосты Host–PCI могут его иметь, а могут и не иметь (подробнее об особенностях мостов говорится в разделе Мосты PCI).
Каждая функция, реализованная в устройстве, имеет своё конфигурационное пространство размером 256 байт, с помощью которого программное обеспечение определяет требования функции к аппаратным ресурсам и, если это возможно, выделяет их. Подробнее регистры конфигурационного пространства и методика настройки устройств описываются в разделе Конфигурирование устройств PCI, здесь же речь пойдёт в основном об обращении к конфигурационному адресному пространству с точки зрения электроники.
В отличие от обращений к адресным пространствам памяти и ввода-вывода, обращения к конфигурационному адресному пространству возможны только со стороны хоста, т.е. моста, соединяющего данный сегмент шины PCI с процессором (возможно, что эта связь осуществляется через другие сегменты шины, расположенные ближе к процессору). В зависимости от того, на каком сегменте шины PCI расположено устройство, к которому относится обращение, применяется один из двух форматов адреса, показанных на рисунке.
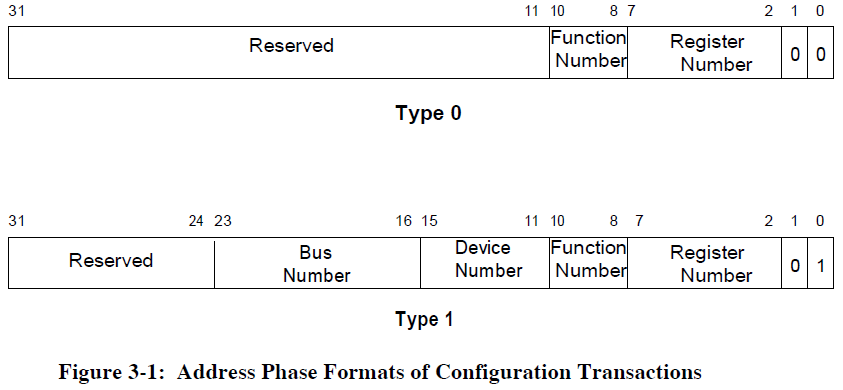
Когда конфигурационная транзакция обращена к устройству, расположенному на данном сегменте шины, хост в фазе адреса генерирует адрес типа 0. Два его младших разряда (биты AD[1:0]) равны нулю, что указывает на использование адреса типа 0, линии AD[10:8] содержат номер функции устройства, а линии AD[7:2] — номер нужного конфигурационного регистра. Выбор устройства на шине обеспечивается соответствующей линией IDSEL (для каждого устройства она своя), поэтому включать номер устройства в состав адреса нет нужды.
Примечание. Разряды AD[31:11] отмечены на рисунке как зарезервированные, но, согласно тексту спецификцаии, на самом деле по ним передаётся декодированный номер устройства, причём установленным может быть только один разряд, соответствующий устройству, которому адресован запрос. Однако для обнаружения адресованного ему запроса устройство должно использовать сигнал IDSEL, а не разряды AD[31:11]], хотя технически хост может просто дублировать линии AD[31:11] в виде сигналов IDSEL. Связь между номерами устройств и разрядами AD[31:11] неясна: по одним отрывкам из спецификации можно сделать вывод, что 11-й разряд адреса соответствует устройсту 0, 12-й — устройству 1 и т.д., по другим — что линию IDSEL для устройства 0 можно подключить к AD[16], для устройства 1 — к AD[17] и т.д.
Если адресуемое устройство расположено в другом сегменте шины, используется адрес типа 1. В его разрядах AD[1:0] содержится комбинация 01, задающая тип адреса. Помимо номеров функции и регистра, занимающих те же позиции, что в адресе типа 0, адрес типа 1 содержит номера шины и устройства (разряды AD[23:16] и AD[15:11] соответственно). Старший байт адреса зарезервирован и должен быть равен нулю. Конфигурационная транзакция с типом адреса 1 передаётся через соответствующий мост на нужный сегмент шины, причём в этом сегменте будет использоваться адрес типа 0. При необходимости конфигурационная транзакция, как и транзакции других типов, проходят по нескольким шинам и соединяющим их мостам: каждый мост «знает», какие диапазоны адресов каждого типа он должен пропускать через себя.
Если устройство, которому адресована конфигурационная транзакция, является однофункциональным, оно может отвечать на транзакцию при любом значении номера функции либо игнорировать транзакции, обращённые к функциям 1–7, принимая лишь обращённые к нулевой функции. Многофункциональные устройства всегда полностью декодируют номер функции и отвечают на транзакцию лишь в том случае, если функция с указанным номером в них реализована.
Ответом устройства на «свою» транзакцию является выдача сигнала #DEVSEL, получив который, хост знает, что транзакция дошла до цели. Отсутствие этого сигнала в течение разумного промежутка времени воспринимается хостом как отсутствие устройства с заданным номером, что приводит к прекращению транзакции (master-abort). Если это была конфигурационная запись, никаких последствий она не имеет, если же это было конфигурационное чтение, процессору возвращаются все единицы.
Номер регистра задаёт адрес конфигурационного регистра размером двойное слово. Функция должна позволять считывать и записывать произвольные байты в пределах двойного слова (для определения, какие байты реально участвуют в операции, используется состояние линий C/BE#). Поддерживать пакетный обмен данными с конфигурационным пространством функция не обязана. Если хост пытается выполнить пакетную передачу, а функция её не поддерживает, последняя выполняет одну фазу данных и прекращает транзакцию путём отсоединения (disconnect). Прерывать такую транзакцию (target-abort) нельзя, поскольку попытка выполнения пакетной передачи не является ошибкой.
Если функция поддерживает пакетную передачу конфигурационных данных, передача может производиться только в режиме линейного приращения адреса, поскольку разряды адреса AD[1:0] заняты индикатором типа адреса (00) и не могут использоваться для указания режима передачи, как это имеет место в операциях чтения и записи адресного пространства памяти.
Использование сигналов разрешения байтов[]
64-разрядный задатчик должен уметь генерировать 32-разрядные транзакции, если он должен взаимодействовать с 32-разрядным устройством (подробно особенности 64-разрядных устройств будут описаны отдельно). Однако запросы с разрядностью, меньшей 32, всегда выполняются как 32-разрядные. Чтобы указать, какие именно байты адресованного двойного слова участвуют в операции, используются линии C/BE[3:0]#. Каждый бит этой линии соответствует одному байту данных, передаваемых по AD[31:0]. Когда бит C/BE# равен нулю, соответствующий байт участвует в операции, когда равен единице — не участвует (тем не менее, соответствующие разряды AD должны содержать стабильное значение, используемое наравне с действительными байтами для контроля передачи по чётности). Для каждой фазы данных в транзакции может использоваться своё значение линий C/BE[3:0]#. Эти сигналы должны быть действительными на момент прихода сигнала CLK, по которому начинается очередная фаза данных, и сохранять своё значение до её окончания; их смена допустима лишь между фазами данных. Разрешены фазы данных, в которых все байты являются неиспользуемыми, т.е. на линиях C/BE[3:0]# установлено значение 1111; такие транзакции не влияют на состояние исполнителя, однако сопровождаются передачей «пустой» информации, контролируемой по чётности.
Спецификация PCI допускает чтение и запись несмежных байтов. Однако некоторые устройства, например, мосты, связывающие PCI с шинами других типов, могут не поддерживать подобные обращения. Мост к шине расширения может в таком случае либо сигнализировать об ошибке с помощью сигнала SERR#, либо разбить обращение к несмежным байтам на несколько обычных обращений и передать их на «свою» шину. Если устройство PCI не поддерживает несмежные обращения в своё пространство ввода-вывода, оно прерывает транзакцию (target-abort).
Устройства, поддерживающие предварительную выборку (prefetching), должны в каждой операции чтения выдавать все байты двойного (или учетверённого для 64-разрядных операций) слова независимо от состояния линий C/BE#. Предвыборку могут поддерживать только такие устройства, чтение информации из которых не ведёт к её разрушению или к изменению состояния устройства.
Владение линиями и оборотные циклы[]
При смене устройства, осуществляющего управление той или иной линией, необходимо некоторое время, чтобы на этой линии снова установился правильный уровень. На временных диаграммах этот промежуток, называемый оборотным циклом (turnaround cycle), обозначается круговыми стрелками, головы которых упираются в их хвосты. Для разных сигналов оборотные циклы могут происходить в разное время. Например, для IRDY#, TRDY#, DEVSEL#, STOP# и ACK64# оборотным циклом является фаза адреса, в течене которой эти сигналы не используются, а значит, их значение безразлично. В качестве оборотного цикла для сигналов FRAME#, REQ64#, C/BE[7:0]#, AD[63:0] используется состояние бездействия шины между транзакциями. Оборотный цикл для LOCK# имеет место в следующем такте после того, как текущий владелец этого сигнала освобождает его. Оборотный цикл для сигнала PERR# является четвёртым после последней фазы данных.
Порядок выполнения транзакций[]
Порядок выполнения транзакций на шине PCI основывается на достижении трёх целей. Во-первых, он удовлетворяет правилам упорядочивания записей модели «производитель–потребитель». Это означает, что результаты операций записи со стороны производителя будут видны потребителю только в том порядке, в каком записи были выполнены производителем. Однако записи нескольких производителей, имеющих разных потребителей, не обязаны быть упорядоченными по отношению друг ко другу, т.е. допускается переупорядочивание операций записи, исходящих от разных задатчиков и адресованных разным исполнителям. Во-вторых, он позволяет откладывать (post) некоторые транзакции с целью увеличения производительности. Наконец, в-третьих, он позволяет избежать мёртвых блокировок (deadlocks) шины, связанны с необходимостью сначала выполнить сброс буферов отложенной записи.
Порядок выполнения некоторой транзакции по отношению к другим транзакциям определяется временем её окончания, т.е. временем выполнения передачи данных. Транзакции, прекращённые с запросом повторения (terminate with Retry), не окончены, поскольку передача данных не выполнена, и поэтому не требуют упорядочивания по отношению друг к другу. Транзакции, прерванные по инициативе задатчика (Master-Abort) или исполнителя (Target-Abort), считаются оконченными с или без передачи данных и больше задатчиком не повторяются. Система может принимать запросы в любом порядке, оканчивая один и продолжая повторять другой. Если задатчику требуется, чтобы одна транзакция была гарантированно завершена раньше другой, он не должен начинать вторую транзакцию до окончания первой. Если задатчик в каждый момент времени имеет одну активную транзакцию, его транзакции будут всегда завершаться в системе в том порядке, в каком они выдавались.
Транзакции по отношению к их выполнению промежуточными звеньями шины (мостами) делятся на откладываемые (posted) и неотложные (non-posted). К первым относятся операции записи в память и записи в память с инвалидацией. Промежуточный мост может задержать выполнение такой транзакции, известив задатчика о её успешном завершении, и выполнить операцию «задним числом»; к моменту фактического окончания откладываемой транзацкии задатчик может выполнить ещё несколько подобных транзакций. В частности, мост может объединить несколько транзакций записи в одну, и лишь тогда выполнить её физически. Остальные виды транзакций (чтение из памяти, а также все виды доступов к пространству ввода-вывода и конфигурационному пространству) являются неотложными: задатчик не может продолжать работу до тех пор, пока начатая им транзакция не будет реально завершена.
Порядок выполнения транзакций простыми устройствами[]
Простым считается такое устройство, которое, выполняя роль задатчика шины PCI, не откладывает операции записи путём накопления данных в буфере своего шинного интерфейса. Когда такому устройству потребуется выполнить запись, оно действительно запрашивает управление шиной и, получив его, выполняет запись, и лишь после этого переходит к выполнению других своих операций. Не следует смешивать накопление данных в буфере шины с использованием внутреннего кэша, функции которого не связаны напрямую с передачей данных по на шине. Например, контроллер диска может использовать внутренний кэш, однако операция ввода-вывода будет считаться выполненной только тогда, когда данные будут реально переданы по шине PCI, в то время как при откладывании записи на уровне шинного интерфейса устройство может считать операцию выполненной, когда завершена «логическая» запись в буфер шинного интерфейса, даже если физически данные по шине ещё не переданы.
Простое устройство должно быть способным выполнять операции шины в роли задатчика и в роли исполнителя независимо друг от друга, т.е. оно не может ставить завершение транзакции в роли исполнителя в зависимость от завершения транзакции в роли задатчика. Так, контроллер диска должен быть готов в любой момент выполнить транзакцию как исполнитель (например, выдать процессору содержимое своего регистра состояния), даже если он ещё не выполнил необходимую для окончания операции ввода-вывода транзакцию как задатчик (например, не записал в ОЗУ считанные с диска данные).
Простые устройства могут прекращать транзакцию с запросом повтора (Retry) только для выполнения этой транзакции как задержанной либо при возникновении условий, препятствующих её исполнению в данный момент, но которые за разумное время будут устранены (например, графический контроллер может прервать транзакцию с повтором из-за того, что ему нужно дождаться обратного хода луча). Простые устройства не поддерживают доступы с блокировкой и не используют сигнал LOCK#.
Порядок выполнения транзакций мостами[]
Мостом является любое устройство, которое может откладывать исходящие операции записи в память (т.е. операции, в которых мосты с точки зрения шины выступают в качестве задатчика). Обычно мосты соединяют две шины PCI, главную шину (т.е. центральный процессор) и шину PCI либо шину PCI и шину специализированного процессора.
Мостам разрешается откладывать транзакции записи в память, проходящие через мост в любых направлениях. Однако, чтобы гарантировать правильный порядок выполнения записей, а также во избежание мёртвой блокировки шины при попытке моста опорожнить внутренние буферы отложенной записи необходимо соблюдать следующие требования:
- отложенные записи в память, проходящие через мост в одном направлении, будут завершены на целевой шине в том же порядке, в каком были завершены породившие их транзакции на исходной шине. Даже если данные были получены мостом как единый пакет, а реально записывать их приходится несколькими транзакциями из-за неспособности исполнителя получить весь пакет целиком, фазы данных, адресованные исполнителю, должны завершаться в том же порядке, в каком завершались соответствующие фазы данных при передаче информации в мост. Например, если процессор через мост осуществляет запись сначала в ячейку A, потом в B и затем в C, именно в таком порядке эти записи будут реально выполнены, хотя могут быть задержаны внутри моста на некоторое время; при этом процессор продолжает свою работу дальше, как будто эти записи уже были выполнены;
- порядок выполнения транзакций записи, следующих через мост в одном направлении, никак не связан с порядком выполнения записей в обратном направлении;
- буферы отложенной записи обоих направлений должны быть опустошены перед окончанием транзакции чтения в любом направлении, т.е. операция чтения сначала «проталкивает» данные, находящиеся во внутренних буферах моста, а уже затем выполняется сама;
- мост в роли исполнителя может связывать возможность выполнения транзакции записи в память с завершением ранее начатой им как задатчиком операции только в том случае, если начатая мостом операция выполняется с блокировкой и соединение с исполнителем уже было установлено. В остальных случаях мост может отвергать адресованные ему транзакции записи в память только в том случае, если это связано с какими-то временными обстоятельствами, которые будут в разумный срок устранены (например, при выполнении опорожнения внутренних буферов).
Помимо транзакций записи в память, мост Host–PCI может откладывать транзакции записи в пространство ввода-вывода, инициированные хостом, обеспечивая при этом их выполнение в том же порядке, в каком они поступили.
Поскольку операции записи в память могут откладываться любыми мостами, а операции записи в пространство ввода-вывода — мостом Host–PCI, задатчик не может точно определить, в какой момент времени такая транзакция была реально завершения. Драйвер устройства, желающий убедиться в доставке его записей устройству, должен выполнить чтение из этого же устройства, поскольку операция чтения «протолкнёт» записи, если они были задержаны мостами.
Запросы прерываний с помощью сигналов INTx# не являются транзакциями шины и поэтому никак не связаны с порядком выполнения транзакций. Появление такого прерывания от устройства не даёт никаких гарантий, что предыдущие операции записи в это устройство были полностью завершены. Запросы прерываний с помощью механизма MSI технически являются транзакциями записи в память, инициируемыми устройствами, и подчиняются обычным правилам для транзакций записи в память.
Объединение транзакций[]
В некоторых случаях мосты могут объединять несколько транзакций записи в память в одну транзакцию большего размера. В спецификации для обозначения объединения используются три термина: combining (комбинирование), merging (слияние) и collapsing (сворачивание).
Комбинирование (combining) происходит, когда последовательные транзакции записи в память преобразуются в одну транзакцию, использующую линейное приращение адреса. Комбинирование возможно только в том случае, если при этом записи в память будут выполняться в том же порядке, в каком они выполнялись в исходных транзакциях. Например, запись двойных слов 1, 2 и 4 может быть выполнена как комбинированная транзакция, а запись двойных слов 4, 2, 1 — не может и должна выполняться как три независимые транзакции. В пакетах допускается появление фаз данных, не содержащих ни одного действительного байта данных. Например, при записи двойных слов 1, 2 и 4 в одной транзакции будет также формально записано двойное слово 3, которое фактически отсутствует, что будет отражено соответствующей установкой сигналов C/BE#. Любое устройство должно допускать комбинирование адресованных ему операций записи в память.
Если исполнитель не способен производить приём информации в виде пакетов, он прекращает транзакцию с отключением (disconnect) после каждой фазы данных. В этом случае мост-задатчик вновь начинает её, но уже с нового места, благодаря чему запись в память всё равно будет выполнена в полном объёме, но за несколько транзакций.
Слияние (merging) подразумевает объединение нескольких операций записи в подряд расположенные байты и/или слова в одну запись двойного или учетверённого слова. Устройство, которому адресованы эти записи, должно допускать предварительную выбору (prefetch), а каждый байт должен занимать своё собственное место в объединённом двойном или учетверённом слове (не допускается слияние записей по одному и тому же адресу). В отличие от комбинирования, порядок следования байтов/слов не важен. Так, запись байтов 3, 1, 0 и 2 может быть преобразована в запись одного двойного слова, т.е. в реальности все четыре байта будут записаны одновременно, хотя задатчик выдавал их последовательно. Если устройство не допускает слияние записываемых байтов, оно должно быть помечено как не обеспечивающее предварительную выборку (non-prefetchable).
Комбинирование и слияние могут выполняться независимо друг от друга. Например, записываемые байты могут сливаться в двойные слова, а последние — комбинироваться в одну транзакцию; при этом, естественно, требуется, чтобы байты, из которых состоят двойные слова, записывались в порядке возрастания номеров двойных слов. Рекомендуется применять их всегда, когда это возможно, для увеличения эффективности использования шины.
Сворачивание (collapsing) имеет место, когда происходит запись в одни и те же ячейки памяти, и заключается в преобразовании нескольких таких записей в одну. В отличие от комбинирования и слияния, сворачивание обычно недопустимо. Оно может применяться лишь к явно указанным диапазонам адресов. Как именно происходит определение этих диапазонов, спецификацией PCI не оговаривается.
Транзакции[]
В этом разделе дано описание и приведены временные диаграммы выполнения 32-разрядных транзакций разных типов. Сигналы, изображаемые сплошными линиями, управляются каким-либо устройством. Сигналы, изображённые пунктиром, не имеют управляющего ими устройства, однако могут иметь определённый уровень (высокий), если для них предусмотрены подтягивающие резисторы. Те сигналы, чьё значение во время отсутствия управления не определено (например, C/BE# и AD), изображаются пунктирными линиями, расположенными между низким и высоким уровнями, а те, которые подтягиваются к высокому уровню, изображаются пунктиром, находящимся на высоком уровне. Стрелки, «кусающие себя за хвост», показывают оборотные циклы (см. выше).
Команды шины[]
Тип транзакции указывается в фазе адреса значением линий C/BE[3:0]#, по которым в этот момент передаётся код команды шины. Всего предусмотрено 12 команд:
| C/BE[3:0]# | Команда |
| 0000 | Подтверждение прерывания |
| 0001 | Специальный цикл |
| 0010 | Чтение ввода-вывода |
| 0011 | Запись ввода-вывода |
| 0100 | Резерв |
| 0101 | Резерв |
| 0110 | Чтение памяти |
| 0111 | Запись в память |
| 1000 | Резерв |
| 1001 | Резерв |
| 1010 | Чтение конфигурации |
| 1011 | Запись конфигурации |
| 1100 | Чтение памяти множественное |
| 1101 | Двойной адресный цикл |
| 1110 | Чтение памяти линейное |
| 1111 | Запись в память и инвалидация |
Команда подтверждения прерывания является операцией чтения, неявно адресованной системному контроллеру прерываний. Значение на линиях AD во время фазы адреса не играет роли; во время фазы данных по этим линиям контроллер прерываний возвращает вектор. Размер вектора указывается линиями C/BE#.
Специальный цикл является широковещательным сообщением, не имеющим конкретного адресата и может использоваться для управления работой шины.
Команды чтения и записи вызывают доступ к соответствующему адресному пространству. При обращении в конфигурационное пространство выбор устройства-исполнителя осуществляется аппаратно генерируемым сигналом IDSEL. Обращения к пространствам памяти и ввода-вывода отслеживаются исполнителями самостоятельно путём анализа всех линий AD во время фазы адреса каждой транзакции. При обращении к пространству ввода-вывода на этих линиях указывается адрес порта с точностью до байта; при обращении к памяти задаётся адрес двойного слова, а биты AD[1:0] используются для указания способа выполнения транзакции в пакетном режиме.
Команда множественного чтения памяти аналогична обычной команде чтения, но указывает исполнителю, что в одной транзакции будет выполняться чтение большого объёма информации (больше, чем длина одной строки кэша). Команда линейного чтения памяти также аналогична обычной команде чтения, но указывает, что задатчик хочет прочитать полную строку кэша. Наличие этих команд позволяет оптимизировать выполнение операции чтения: если выполняется обычная команда чтения, мост-задатчик не может запросить у устройства-исполнителя больше данных, чем явно определено в операции, в то время как в этих командах можно запрашивать сразу целую строку кэша, поскольку инициатор обмена (обычно процессор) гарантирует, что весь считываемый объём допускает предварительную выборку.
Команда записи в память с инвалидацией аналогичная обычной команде записи, но гарантирует, что задатчик запишет полную строку кэша в одной транзакции. В этой команде в каждой фазе данных линиями C/BE# должны быть разрешены все байты. Пересечение границы строки кэша допустимо только в том случае, если следующая строка также будет записана полностью.
Двойной адресный цикл (DAC) используется для передачи 64-разрядного адреса по 32-разрядной шине. В первом цикле фазы адреса передаётся младшая половина адреса и код команды DAC, во второй фазе — старшая половина адреса и код команды, которая должна быть выполнена. Если исполнитель поддерживает только 32-разрядную адресацию, он должен игнорировать такую транзакцию.
Все устройства PCI, за исключением моста Host–PCI, должны уметь выполнять команды конфигурационного чтения и записи; остальные команды являются необязательными. Если устройство как исполнитель обеспечивает выполнение команды чтения из памяти, оно обязано реализовать все разновидности команды чтения из памяти, однако может выполнять их упрощённым способом — как обычное чтение независимо от того, какая именно разновидность используется. Аналогично, устройство, готовое исполнить команду записи в память, должно уметь выполнять также запись с инвалидацией, при необходимости трактуя её как обычную запись.
Если задатчик может генерировать команду записи в память с инвалидацией, у него должен иметься регистр размера строки кэша (Cacheline Size).
Транзакция чтения[]
На рисунке приведена временная диаграмма транзакции чтения. Транзакция начинается фазой чтения, с появления сигнала FRAME#, что имеет место во время второго синхроимпульса. Одновременно с FRAME# задатчик выставляет адрес исполнителя на линии AD и код команды на линии C/BE#. Исполнитель, опознав свой адрес, выдаёт сигнал DEVSEL# (в приведённом примере это происходит либо к третьему, либо к четвёртому такту — такт 3 в любом случае используется для ожидания, см. ниже).

Первая фаза данных начинается с третьего такта. Она требует оборотного цикла для линий AD, поскольку в фазе адреса ими управлял задатчик, а в фазах данных должен управлять исполнитель. Поэтому такт 3 используется для ожидания передачи управления этими линиями от задатчика к исполнителю, однако исполнитель сразу указывает, что готов принять данные, выставив сигнал IRDY#.
По линиям C/BE# передаётся информация о том, какие байты реально участвуют в операции. Поскольку в пакетном чтении обычно используются все байты, на рисунке возможные переходы состояния линий C/BE# не показаны (они присутствуют на временной диаграмме транзакции записи, см. ниже). Состояние линий C/BE# является правильным в течение всей фазы данных независимо от состояния линии IRDY# и меняется сразу после окончания одной фазы данных (на момент поступления первого тактового сигнала новой фазы линии C/BE# уже действительны).
Исполнитель, получив управление линиями AD, сразу выставляет на них данные, читаемые в первой фазе данных, и сигнализирует об этом сигналом TRDY# (4-й такт), чем заканчивается первая фаза данных.
Задатчик в момент окончания первый фазы данных не снимает сигнал IRDY#, говоря этим, что готов сразу принять следующее двойное слово данных. Однако исполнитель не готов их выдать, поэтому убирает сигнал TRDY#, что приводит к образованию такта ожидания 5. На 6-м такте исполнитель выдаёт данные на AD и выставляет сигнал TRDY# — вторая фаза данных завершена.
Между второй и третьей фазами данных задатчик снимает сигнал IRDY#, сигнализируя этим, что он пока не готов принять очередную порцию данных. Тем не менее, исполнитель на этот раз выдаёт данные сразу после окончания второй фазы, поэтому сигнал TRDY# он не убирает (такт 7). Задатчик, придя в состояние готовности, выдаёт сигнал IRDY#. Поскольку данные к этому моменту уже выданы исполнителем, третья фаза данных завершается (такт 8).
Задатчик снимает сигнал FRAME# перед окончанием последней фазы данных, т.е. в такте 8. Хотя задатчик знает, что третья фаза данных является последней, уже в такте 7, когда эта фаза начинается, он не может снять FRAME#, поскольку он снял IRDY#, вводя такт ожидания. Когда же он выставляет IRDY#, свидетельствуя о своей готовности принять данные и закончить фазу данных, он снимает FRAME#, указывая, что эта фаза данных является последней.
Когда завершается последняя фаза данных, исполнитель убирает свои сигналы TRDY# и DEVSEL#, а также отдаёт управление линиями AD. Задатчик одновременно с этим снимает сигнал IRDY#. 9-й такт используется в качестве оборотного цикла для сигналов FRAME#, AD# и C/BE#, после чего может начинаться следующая транзакция.
Транзакция записи[]
Порядок выполнения операций в транзакции записи подобен таковому в транзакции чтения. Главным отличием является отсутствие оборотного цикла для линий AD, поскольку управление ими остаётся у задатчика.
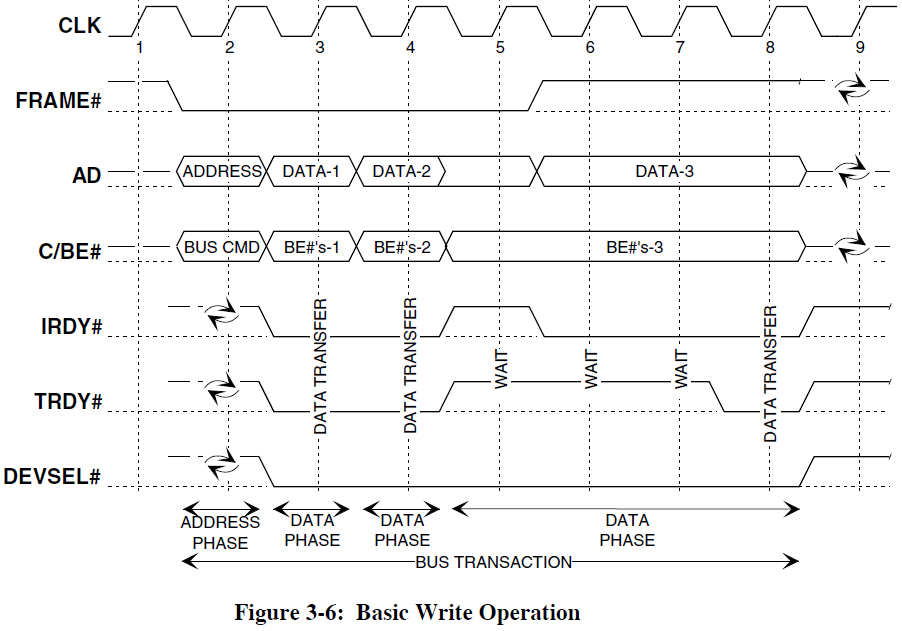
В приведённой временной диаграмме показано изменение состояния линий C/BE# в каждой фазе данных. Аналогичное изменение может иметь место и в транзакции чтения, хотя там пакетное чтение обычно производится полными двойными (или учетверёнными) словами. Ещё одним заслуживающим внимания моментом является снятие сигнала FRAME# одновременно с выдачей IRDY# в проследней фазе данных.
Прекращение транзакции[]
Транзакции могут прекращаться по инициативе как задатчика, так и исполнителя.
Прекращение по инициативе задатчика[]
Задатчик прекращает транзакцию, снимая сигнал FRAME# при активном сигнале IRDY#. Это событие указывает исполнителю, что выполняется последняя фаза данных. После передачи последней порции данных при активных сигналах IRDY# и TRDY# задатчик снимает сигнал IRDY# и транзакция оканчивается переходом шины в состояние бездействия.

Такое прекращение транзакции происходит по одной из двух причин:
- окончание операции (completion) — обычное прекращение транзакции, связанное с логическим завершением операции, т.е. приёмом или передачей всего запланированного объёма данных;
- таймаут (timeout) — прекращение операции в связи с тем, что адресованный текущему задатчику сигнал GNT# был снят, после чего оказался исчерпан интервал задержки прекращения операции (latency timer). Операция, выполняемая задатчиком, может быть логически ещё не завершена, поэтому в будущем её выполнение может быть возобновлено с момента прекращения. Запись в память с инвалидацией не может быть прервана на середине строки кэша, поэтому она прекращается по таймауту при выполнении не двух, а трёх условий: снят сигнал GNT#, исчерпан таймер задержки и достигнут конец очередной строки кэша.
На приведённой выше временной диаграмме показано нормальное окончание транзакции, применимое к обоим описанным случаям. Если имеет место логическое завершение операции, сигнал FRAME# снимается задатчиком при активном сигнале IRDY# (такт 3) по той причине, что начинающаяся фаза данных будет последней. Когда исполнитель выставит сигнал TRDY# (на диаграмме этот сигнал уже активен в такте 3, но это не обязательно: исполнитель может быть не готов немедленно выполнить фазу данных, и в этом случае в течение нескольких тактов TRDY# может быть неактивным), фаза данных, а вместе с ней и транзакция завершается: задатчик снимает сигнал IRDY# при уже снятом сигнале FRAME#, и шина переходит в состояние бездействия (такт 4).
Если транзакция прекращается по таймауту, сигнал FRAME# снимается, когда уже был снят сигнал GNT# (это произошло в такте 2 или раньше), был исчерпан счётчик задержки (этот момент отражён надписью T/O, которая отнесена к такту 2 на левой диаграмме и к такту 1 на правой) и задатчиком был выставлен сигнал IRDY#, свидетельствующий о его готовности выполнить фазу данных. Все эти условия на обеих диаграммах выполняются в такте 3.
Если исполнитель, которому адресована транзакция, не отвечает за разумное время, задатчик прерывает её (master-abort).

Не обнаружив ответа исполнителя (сигнал DEVSEL# отсутствует), задатчик снимает сигнал FRAME#, а в следующем такте — и IRDY#, после чего шина переходит в состояние бездействия. Заметим, что сигнал FRAME# не может сниматься при неактивном сигнале IRDY#, а последний должен сниматься как минимум через такт после снятия FRAME#. Минимальное время ожидания ответа устройства с момента выдачи сигнала FRAME# составляет пять тактов, т.е. задатчик может снимать FRAME# в такте 6, однако он может продолжать ожидать ответа устройства ещё некоторое время (на приведённой диаграмме он прекращает транзакцию снятием сигнала FRAME# в такте 7). Если устройство ответит сигналом DEVSEL# до снятия FRAME# (до такта 6 включительно на приведённой диаграмме), задатчик не может прервать транзакцию и должен выполнить хотя бы одну фазу данных.
На ПК мосты при прерывании транзакции записи просто отбрасывают данные, а при прерывании транзакции чтения возвращают все единицы; факт прерывания транзакции отражается лишь установкой соответствующего разряда в регистре состояния моста. Другие устройства-задатчики, если они не могут сообщить о прерывании транзакции драйверу, вырабатывают сигнал SERR#. На системах других архитектур мосты могут вырабатывать сигнал ошибки. Когда прерывание транзакции происходит при попытке предварительной выборки данных, т.е. когда реально эти данные ещё не были затребованы, возникновение ошибки не регистрируется.
Прекращение по инициативе исполнителя[]
Исполнитель может досрочно прекращать транзакцию, используя сигнал STOP#. Предусмотрено три вида прекращения транзакции по инициативе исполнителя:
- повтор (retry) — прерывание транзакции до передачи каких-либо данных из-за того, что в данный момент исполнитель занят и не может выполнить транзакцию. Чтобы прекратить транзакцию этим способом, исполнитель в первой фазе данных выдаёт сигнал STOP# без сигнала TRDY#. STOP# не может быть выдан в оборотном цикле сигналов AD, который имеет место в транзакции чтения. Получив сигнал STOP#, задатчик прекращает транзакцию (убирает сигнал FRAME#, а затем IRDY#), но позже повторит её;

- отсоединение (disconnect) имеет место, когда исполнитель прекращает транзакцию, выполнив одну или несколько фаз данных. Нужда в отсоединении возникает в том случае, если исполнитель по каким-либо причинам не поддерживает обмен данными в пакетном режиме или вынужден его прервать. Отсоединение выполняется в любой фазе данных путём либо одновременной выдачи сигналов STOP# и TRDY# (так называемое отсоединение с данными — disconnect with data, когда происходит обычная передача данных, после чего транзакция сразу завершается), либо путём снятия сигнала TRDY# и выдачи STOP# (отсоединение без данных — disconnect without data; может выполняться в любой фазе данных, кроме первой, и означает прекращение транзакции без передачи данных в этой последней фазе). Через некоторое время задатчик инициирует новую транзакцию, в которой передача данных будет продолжена с точки, где она была прервана исполнителем через отсоединение;
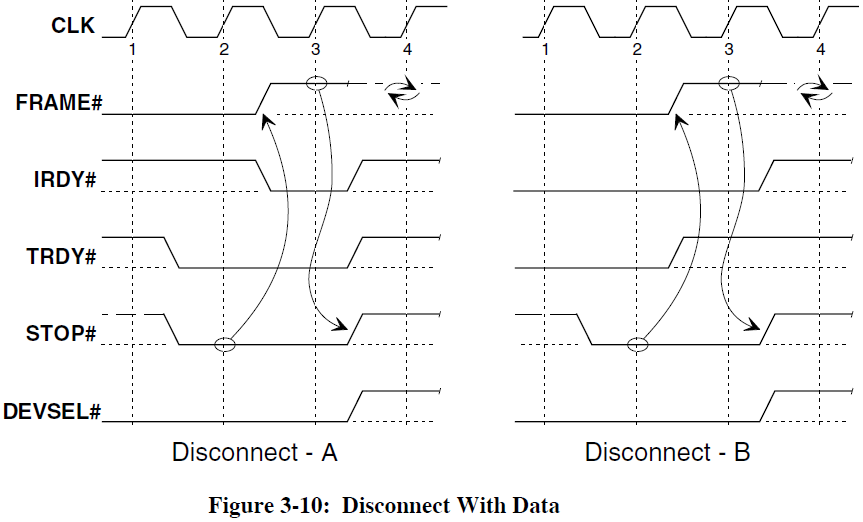


- отмена (target-abort) — ненормальное прекращение транзакции, означающее, что исполнитель в принципе не может её выполнить. Исполнитель сигнализирует об отмене транзакции путём одновременной выдачи сигнала STOP# и снятия DEVSEL#.

Обычно устройства реализуют как минимум способность прекращения транзакции с повтором. Повтор может быть не реализован в очень простых исполнителях, которые:
- не поддерживают доступ с блокировкой;
- не располагают буфером отложенной записи;
- не могут перейти в состояние, когда они окажутся не готовыми ответить на транзакцию.
Исполнитель может всегда завершать транзакцию путём отсоединения с данными (одновременной выдачей TRDY# и STOP#) в первой фазе данных, даже если задатчик не пытался выполнить пакетную передачу (т.е. если сигнал FRAME# был снят им в начале первой и единственной фазы данных). Временная диаграмма такой транзакции показана ниже:

Когда транзакция прекращается с повтором или отсоединением, задатчик должен снять сигнал REQ#, а потом выставить его повторно, и лишь после прихода нового разрешения GNT# он может вновь начать транзакцию, чтобы продолжить прерванную передачу данных. Сигнал REQ# должен сниматься минимум на два такта.
Устройство, в состав которого входит несколько задатчиков, разделяющих общий выход REQ#, не обязано убирать сигнал REQ#, когда транзакция прекращается по инициативе исполнителя. Если с прекращением транзакции сигнал GNT# не был убран, такое устройство может сразу за прекращённой начать следующую транзакцию, однако последняя не может быть продолжением прерванной (т.е. должна исходить от иного задатчика или адресоваться другому исполнителю). Для возобновления прерванной передачи всё равно требуется убрать сигнал REQ# как минимум на два такта и ждать поступления сигнала GNT#.
Если исполнитель выдаёт сигнал STOP# в последней фазе данных транзакции, т.е. если на самом деле имеет место нормальное завершение, а не отсоединение, задатчик не обязан снимать сигнал REQ#: он может сразу перейти к выполнению следующей запланированной им транзакции.
Если исполнитель прекратил транзакцию с запросом повторения, задатчик обязан повторять её до успешного выполнения тем же самым способом, каким он пытался выполнить транзакцию впервые. Это означает, что должна использоваться та же самая команда, тот же адрес (включая разряды AD[1:0]), те же разрешённые байты, те же самые данные в случае операции записи (в том числе в неиспользуемых байтах), а также те же значения сигналов LOCK# и REQ64#.
Задатчик должен стараться повторить транзакцию, прерванную исполнителем с запросом повтора, как можно быстрее, желательно в течение 33 тактов. В некоторых случаях, однако, задатчик может оказаться не в состоянии повторить транзакцию (например, в промежутке между попытками повтора программное обеспечение запретило устройству выступать в роли задатчика). Реакция исполнителя на подобные ситуации будет описана ниже, в подразделе, посвящённом задержанным транзакциям.
Задатчик не обязан повторять транзакцию сразу после её прекращения исполнителем, он может сначала выполнить какую-либо другую транзакцию, адресованную иному исполнителю или же сам выступить в роли исполнителя. Независимо от степени завершённости другой транзакции и от возникших при её выполнении ошибок он должен в конечном счёте повторить первую транзакцию.
Задержанные транзакции[]
Задерживание транзакций (transaction delaying) применяется исполнителями, неспособными завершить первую фазу данных транзакции в соответствии с требованиями спецификации PCI. Задержанная транзакция появляется в результате прекращения транзакции исполнителем с запросом повтора (terminate with retry). Однако если «честный» запрос повтора связан с тем, что исполнитель в момент поступления запроса просто не может его обслужить, то задерживание транзакции применяется с иной целью: дать исполнителю время выполнить запрошенную операцию, не удерживая при этом шину. Задерживание транзакций может использоваться двумя типами устройств: контроллерами ввода-вывода и мостами. В общем случае контроллеры могут обрабатывать только одну задержанную транзакцию, а мосты — несколько.
Одним из преимуществ использования задержанных транзакций является повышение пропускной способности шины: если устройство не способно немедленно выполнить транзакцию, оно её завершает с повтором, а не вводит такты ожидания, впустую удерживая шину. Благодаря этому появляется возможность выполнить на шине другую транзакцию, а затем завершить задержанную. Другим преимуществом является возможность отложить реальное выполнение записи в память, пока это действительно не потребуется: при появлении транзакции, требующей выгрузки буферов отложенной записи, эта транзакция будет задержана, после чего произойдёт выгрузка буферов, реальное выполнение задержанной транзакции, а затем и её нормальное окончание, когда задатчик вновь повторит эту транзакцию.
Общие принципы выполнения задержанных транзакций[]
Все команды шины, которые должны быть завершены на целевой шине раньше, чем будут завершены на исходной шине, могут завершаться как задержанные транзакции. К ним относятся команды подтверждения прерывания, чтения и записи конфигурационного пространства и пространства ввода-вывода, а также все разновидности чтения памяти. Команды записи в память и записи в память с инвалидацией могут быть завершены на исходной шине раньше, чем на целевой, т.е. быть отложены.
Задержанная транзакция для своего выполнения проходит через три стадии:
- запрос от задатчика;
- завершение запроса исполнителем;
- завершения транзакции задатчиком.
В течение первого шага задатчик генерирует транзакцию, исполнитель обнаруживает её, запоминает информацию, необходимую для завершения запрошенного доступа и прекращает транзакцию с повтором. Запомненная информация о запросе называется задержанным запросом (delayed request). Задатчик не может отличить исполнителя, выполняющего транзакцию как задержанную, от исполнителя, просто не способного в данный момент выполнить транзакцию и поэтому запрашивающего её прекращение с последующим повтором. Поэтому задатчик периодически повторяет такую транзакцию, пока она не будет выполнена.
Во время второго шага исполнитель самостоятельно выполняет запрос, используя информацию, сохранённую им на первом шаге. Если выполнялась операция чтения, исполнитель считывает нужные данные и устанавливает соответствующее ссостояние завершения запроса; если выполнялась операция записи, он записывает данные и опять-таки устанавливает состояние завершения. Результат выполнения задержанного запроса называется задержанным завершением (delayed completion). Исполитель хранит данные задержанного завершения до тех пор, пока задатчик не повторит первоначальный запрос.
На третьем шаге задатчик, получив управление шиной, повторно выдаёт первоначальный запрос. Исполнитель опознаёт его и выдаёт задатчику состояние завершения (а также данные, если выполнялась операция чтения). В этот момент исполнитель отбрасывает данные задержанного завершения, и транзакция считается оконченной. Состояние, возвращённое задатчику, будет в точности то же самое, что получено исполнителем во время выполнения им отложенного запроса (т.е. им может быть отсоединение, ошибка чётности, нормальное завершение и т.п.).
Информация, необходимая для выполнения задерживаемой транзакции[]
Чтобы выполнить задерживаемую транзакцию, исполнитель должен запомнить следующую информацию, поступившую от задатчика:
- адрес;
- команду шины;
- маску разрешения байтов;
- признак чётности адреса и данных, если разряд обнаружения ошибок чётности (бит 6 командного регистра) установлен;
- значение сигнала REQ64# (при 64-разрядной передаче);
- разрешённые байты данных при операции записи.
- состояние линии LOCK# (для мостов в некоторых случаях; особенности мостов рассматриваются отдельно).
Адрес и код команды шины выставляются задатчиком в фазе адреса, маска разрешения байтов — в фазе данных, причём она присутствует независимо от того, выставлен сигнал IRDY# или нет. Байты данных в операции записи выставляются задатчиком также в фазе данных, но, в отличие от маски разрешённых байтов, они действительны только при наличии сигнала IRDY#.
Задатчик обязан повторять транзакцию с точно теми же состояниями на линиях шины, что были при первой попытке её выполнения. Это требование распространяется и на неактивные байты данных в операции записи.
Запомненная для выполнения транзакции информация используется исполнителем, чтобы отличить попытку того же задатчика повторить эту транзакцию от попытки выполнить транзакцию, исходящей от иного исполнителя. В случае транзакции чтения исполнитель может не сравнивать маску разрешения байтов, если он всегда возвращает все байты, помещающиеся на шину (и если при этом чтение информации не имеет побочных эффектов, т.е. допускается предварительная выборка). Если сравнение было успешным и исполнитель уже закончил выполнение транзакции, он отвечает соответствующим образом. Если сравнение было успешным, но исполнитель ещё не закончил операцию, он прекращает транзакцию с запросом повторения и продолжает операцию. Если сравнение было неудачным (поступила транзакция от иного задатчика), исполнитель оканчивает её с запросом повторения, чтобы выполнить её позже. Если несколько задатчиков инициируют совершенно одинаковые транзакции, обращённые к одному исполнителю, последний не нуждается в различении того, от какого именно задатчика транзакция исходит: он просто обрабатывает транзакцию и выдаёт результаты, как только сможет, при этом тот задатчик, на чей запрос не было положительного ответа, будет продолжать повторять транзакцию до её выполнения.
Отбраковка задержанных транзакций[]
Если задатчик не повторяет задержанную транзакцию, она в конце концов будет отброшена (discard) исполнителем, для чего служит специальный таймер отбраковки (Discard Timer). При первоначальной выдаче и каждом повторении транзакции таймер отбраковки, имеющий длину 15 бит, устанавливается в исходное состояние, посче чего ведёт отсчёт счёт с частотой синхронизации шины. Когда он достигнет предела (т.е. 32768 тактов), исполнитель должен будет отбросить транзакцию.
Если отброшенная транзакция была запросом чтения, причём исполнитель допускает предвыборку данных (т.е. чтение не имеет побочных эффектов), рекомендуется не фиксировать возникновение ошибки, поскольку целостность системы при этом не нарушается. Однако, если отброшенная транзакция вызвала нарушение целостности (была транзакцией записи либо чтения, но само чтение ведёт к разрушению информации, т.е. устройство не допускает предвыборку), рекомендуется зафиксировать ошибку и известить об этом драйвер устройства.
Задатчик может выдать одному и тому же исполнителю несколько транзакций. Если исполнитель завершает их с запросом повторения, задатчик обязан повторять их все. Порядок повторения не играет роли, но каждая такая транзакция должна быть повторена до того, как истечёт таймер отбраковки.
Запись в память и задержанные транзакции[]
Устройство, применяющее задерживание транзакций, должно уметь выполнять адресованные ему операции записи в память одновременно с выполнением задержанной транзакции. Оно может при необходимости прекращать транзакцию записи с запросом повторения, но не должно ставить возможность успешного выполнения транзакции записи в зависимость от предварительного завершения задержанной транзакции, иначе возможно возникновение мёртвой блокировки шины.
Поддержка нескольких задержанных транзакций[]
Мосты PCI–PCI, а также некоторые другие устройства, могут поддерживать одновременное выполнение нескольких задержанных транзакций. Их количество спецификацией не определяется и зависит от особенностей реализации устройства. Однако спецификация накладывает определённые ограничения на порядок завершения транзакций в таких устройствах, чтобы соблюдались принципы очерёдности выполнения транзакций и не возникали блокировки шины.
Если устройство приняло к исполнению транзакцию записи в память, оно не может завершить позднее поступившие транзакции любых типов до тех пор, пока не будет завершена эта транзакция записи. Это правило необходимо для обеспечения правильного порядка выполнения транзакций в модели «производитель — потребитель».
Позже начатой транзакции записи в память разрешается завершаться раньше, чем ранее начатым транзакциям других типов. Кроме того, транзакции, обеспечивающие завершение поздно начатых задержанных транзакций, должны иметь возможность выполниться раньше, чем завершатся ранее начатые запросы чтения или записи, за исключением записи в память. Это необходимо, чтобы избежать мёртвых блокировок шины.
Арбитраж шины[]
Спецификация PCI не определяет алгоритм арбитража шины, т.е. порядка её предоставления в распоряжение того или иного устройства. Однако применяемый алгоритм должен обеспечивать выделение шины любому устройству не позднее чётко заданного промежутка времени после поступления запроса от этого устройства на выделение шины. Устройства не обязательно должны иметь равные права на шину, однако ни одно из них не должно иметь возможности её полностью монополизировать.
Каждый потенциальный задатчик в системе имеет свою пару сигналов REQ#/GNT#. Устройство, желающее выступить в роли задатчика, выдаёт связанный с ним сигнал REQ#. Когда арбитр решит предоставить шину этому устройству, он выдаст относящийся к нему сигнал GNT#. Задатчик может начать транзакцию, если он получил свой сигнал GNT#, а шина находится в состоянии бездействия; состояние его сигнала REQ# в этот момент роли не играет.
Арбитраж выполняется независимо от других операций на шине. Устройство, желающее получить шину, может выдавать REQ# в любой момент времени, а арбитр может выдать GNT# даже в тот момент, когда шина используется другим устройством. Появление GNT# означает лишь то, что после завершения текущей транзакции и перехода шины в состояние бездействия следующую транзакцию сможет выполнять устройство, получившее сигнал GNT#.
Сигнал GNT# может быть снят арбитром в любой момент. Его снятие означает, что обмен данными пора заканчивать. GNT# может сниматься с соблюдением следующих правил:
- если GNT# снят в одном цикле с выдачей FRAME#, транзакция шины является корректной и будет продолжена;
- один из сигналов GNT# может быть снят одновременно с выдачей другого сигнала GNT#, если на шине в данный момент выполняется какая-то транзакция. Если же шина находится в состоянии бездействия, между снятием одного GNT# и выдачей другого GNT# должен пройти как минимум один пустой цикл;
- пока сигнал FRAME# отсутствует, GNT# может быть снят в любой момент.
Порядок выполнения транзакций двумя задатчиками показан на рисунке.
стр. 91

Задатчик A, запрашивая получение шины, выставляет свой сигнал REQ# ещё до начала такта 1. Арбитр, разрешая задатчику A начать операцию на шине, выдаёт соответствующий сигнал GNT#, воспринимаемый задатчиком в такте 2. В этот момент FRAME# и IRDY# не выставлены, поэтому задатчик A начинает операцию, сообщая об этом выдачей в такте 3 сигнала FRAME#. Поскольку он желает выполнить несколько транзакций подряд, он оставляет свой сигнал REQ# активным.
Арбитр, получив FRAME#, знает, что задатчик A начал операцию. Однако одновременно присутствует запрос от задатчика B, поэтому арбитр снимает сигнал GNT# для задатчика A (чем извещает его о необходимости закончить операцию после завершения текущей транзакции) и выдаёт сигнал GNT# для задатчика B. Задатчик A, увидев, что его сигнал GNT# снят, заканчивает текущую транзакцию и освобождает шину, снимая сигналы FRAME# и IRDY#.
Задатчик B, получив в такте 4 сигнал GNT#, ожидает освобождения шины, что происходит в такте 5. С этого момента он становится владельцем шины, выдаёт сигнал FRAME# (такт 6) и выполняет запланированную транзакцию. Задатчик B собирается выполнить всего одну транзакцию, поэтому одновременно с выдачей FRAME# снимает свой сигнал REQ#. Если бы он, как и задатчик A, желал выполнить несколько транзакций, он продолжал бы удерживать свой сигнал REQ#.
Арбитр, обнаружив снятие сигнала REQ# от задатчика B, вновь выдаёт сигнал GNT# для задатчика A, который не снимал свой сигнал REQ#. Задатчик A, дождавшись окончания транзакции задатчиком B, вновь получает шину и начинает выполнять свою транзакцию.
Задержки[]
Другие операции шины[]
Обработка ошибок[]
Особенности 64-разрядной шины[]
Литература[]
- PCI Local Bus Specification. Revision 3.0. August 3, 2004
- Tom Shanley and Don Anderson. PCI System Architecture. Fourth Edition. — Addison-Wesley Developer's Press, 1999
- Гук М. Аппаратные интерфейсы ПК. Энциклопедия. — СПб.: Питер, 2002